| パターン |
説明 |
| 文字 |
一つの文字は、正規表現で最も基本的なパターンです。このパターンはその文字自身にマッチします。
たとえば、
A というパターンは、検索対象の文字列に A が含まれている場合にマッチします。
正規表現の中で特別な意味を持つ文字(メタキャラクタと呼びます)を本来の文字として扱う場合には、その直前に ¥ (半角の円記号) または 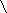 (半角のバックスラッシュ) を置きます。
たとえば、* という文字を検索する場合は * (アスタリスク)がメタキャラクタなのでパターンとして ¥* を指定します。 (半角のバックスラッシュ) を置きます。
たとえば、* という文字を検索する場合は * (アスタリスク)がメタキャラクタなのでパターンとして ¥* を指定します。
ASTEC Eyes の正規表現におけるメタキャラクタは、
¥ ^ $ ( ) | . [ - ] * + ? { , }
の16 文字です。
文字として日本語の文字(Shift JIS コードの2 バイト文字)も指定できます。
|
文字列
(パターンの連結
(concatination))
|
文字を連結した文字列をパターンとして指定できます。
たとえば、flags というパターンは、検索対象に‘f’, ‘l’, ‘a’, ‘g’, ‘s’
という文字がこの順序で現れた場合にマッチします。
文字に限らず一般的なパターンも同様にして連結できます。
パターン R とパターン S を連結したパターン RS は、
R にマッチした直後に S にマッチすることを表します。
|
|
(選択肢
(alternative))
|
パターン R にマッチするか、またはパターン S にマッチするパターンを
R|S と書きます。
foo|bar は、文字列 foo にマッチするかまたは文字列 bar
にマッチするパターンです。
|
*
(閉包
(closure))
|
* の直前のパターンを
0 回以上の任意回数連結したパターンにマッチするパターンを表します。
たとえば ab* は、a, ab, abb, abbb, abbb … b という文字列にマッチします。
|
‘(’および‘)’
(グルーピング)
|
括弧は、パターンのグループを示すために使います。
たとえば、
a(bc)* は、a, abc, abcbc, abcbcbc, abcbcbc…bc という文字列にマッチします。
また foo (bar|baz) は、foobar または foobaz にマッチします。
|
| メタキャラクタ |
機能 |
| . |
任意の一文字にマッチします。
すべての文字を | でつなぎ、
全体を括弧でくくったパターン(a|b|c|…|0|1|2|…|あ|い|う|…)と等価です。
|
| ‘[’および‘]’ |
文字の集合を表します。‘[’と‘]’で囲まれた文字のいずれかとマッチします。
[abc] は、a または b または c とマッチするパターンで、(a|b|c) と等価です。
- (マイナス記号)で文字の範囲を指定できます。
[A-Za-z] は、大文字と小文字のアルファベットいずれかにマッチします。
文字の範囲はASCII コードを基に定義されます。
‘[’の直後に^(サーカムフレックス)を置くと否定の意味になります。
[^0-9] は、数字以外の任意の文字にマッチします。
‘[’と‘]’は、1 バイトASCII コードの集合を表します。
日本語の文字(Shift JIS コードでの2 バイト文字)は、直接表現できません。
‘[’と‘]’で囲まれた場所では、¥ ^ - ]
の4文字以外のメタキャラクタは通常の文字として扱います。
また、[ の直後以外では ^ も通常の文字として扱います。
このとき、これらの文字の直前に ¥
(円記号)を置く必要はありません(置いても意味は変わりません)。
|
| {m ,n } |
直前のパターンの m 回以上、n 回以下の繰り返しを表します。
m は 0 以上の整数、n は1 以上の整数です。
ここでm ≦ n である必要があります。
また、{m ,} は m 回以上の任意回の繰り返しを表します。
{,n } は {0,n } と等価です。
{n } は {n ,n } と等価で、
ちょうど n 回の繰り返しを表します。
|
| ? |
直前のパターンの0回または1回のマッチを表します。
パターン R に対し、R? は R{0,1} と等価です。
|
| + |
直前のパターンを1回以上の任意回数連結したパターンを表します。
パターン R に対し、R+ は RR* または R{1,} と等価です。
|
| ^ |
検索対象文字列の先頭にマッチします。
^foo は、foobar にはマッチしますが、barfoo にはマッチしません。
|
| $ |
検索対象文字列の末尾にマッチします。
foo$ は、barfoo にはマッチしますが、foobar にはマッチしません。
|
¥ (円記号)を前に置くと特別な意味をもつ文字があります。
この ¥ (円記号)と文字の組み合わせは、エスケープシーケンスと呼ばれます。
ASTEC Eyes の正規表現がサポートするエスケープシーケンスの一覧を次に示します。