You can use regular expressions for text search in the [Find] dialog box,
[Option] dialog box, and Decode Result Filter.
| Patterns |
Explanations |
|---|
| Character |
One character is the most fundamental pattern in a regular expression.
An ordinary character except for metacharacters matches the character itself.
For example, the pattern "A" matches the character "A".
The metacharacter (having special meaning in a regular expression)
preceded by 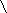 (backslash)
is treated as an ordinary character.
For example,
if you want to search for a character * (asterisk),
you must specify * as a pattern
since * is a metacharacter. (backslash)
is treated as an ordinary character.
For example,
if you want to search for a character * (asterisk),
you must specify * as a pattern
since * is a metacharacter.
metacharacters for ASTEC Eyes regular expression
There are 16 metacharacters for ASTEC Eyes regular expression.
(backslash)
^ $ ( ) | . [ - ] * + ? { , }
You can also use a Japanese character
(Shift JIS encoding, 2 byte character)
as ordinary character with Japanese Windows.
|
Text
(concatenation)
|
You can specify the concatenation of characters as a pattern.
For example,
the pattern flags matches the character sequence of
'f', 'l', 'a', 'g', 's'.
Not only a character but a pattern can be concatenated similarly.
The pattern RS concatenating pattern R and S matches
R followed by S.
|
|
(alternative)
|
Pattern R|S matches either pattern R or S.
foo|bar matches the text foo or bar.
|
*
(closure)
|
A pattern followed by * matches 0 or more occurrences of the pattern.
For example,
ab* matches a, ab, abb, abbb,
abbb ... b, and so on.
|
'(' and ')'
(grouping)
|
Parentheses mean the grouping of patterns.
For example,
a(bc)* matches a, abc, abcbc, abcbcbc,
abcbcbc--bc, and so on.
foo(bar|baz) matches both foobar and foobaz.
|
You can use the following metacharacters with ASTEC Eyes.
| Metacharacters |
Functions |
|---|
|
.
|
. (period) matches any one character.
It is equivalent to the pattern
that all the characters are concatenated and enclosed in the parentheses:
(a|b|c| |0|1|2|| |0|1|2||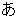 | |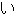 | |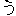 |) |)
|
|
[ and ]
|
A non-empty string of characters enclosed in square brackets matches
any one character in that string.
The pattern [abc] matches a, b, or c.
It is equivalent to the pattern (a|b|c).
The - (minus) is used to indicate a range of consecutive characters.
[A-Za-z] matches one of the alphabets in capital or small letter.
The order of characters is based on the ASCII code.
[ followed by ^ (circumflex) matches one character
except the characters after circumflex.
[^0-9] matches any characters other than a number.
[ and ] make a group of 1 byte ASCII characters.
You can not make a group of Japanese characters (Shift JIS encoding, 2 byte character).
Metacharacters other than , ^, -
and ] are treated as an ordinary character.
In addition,
^ has the special meaning only if it occurs immediately after [.
It is not necessary to escape the metacharacters except the above four with
.
|
|
{m ,n }
|
This pattern matches any number of occurrences
between m and n inclusive of the preceding pattern.
Where m ≥ 0,
n ≥ 1,
and m ≤ n.
{m,} matches at least m occurrences.
{,n} is equivalent to {0, n}.
{n} is equivalent to {n, n},
and matches exactly n occurrences.
|
|
?
|
? matches zero or one occurrence of the preceding pattern.
R? is equivalent to R{0,1}.
|
|
+
|
+ matches one or more occurrences of the previous pattern.
R+ is equivalent to RR* and R{1,}.
|
|
^
|
A ^ (circumflex) at the beginning of an entire pattern
matches the beginning of the target text.
^foo matches foobar,
but does not match barfoo.
|
|
$
|
A $ (dollar) at the end of an entire pattern
matches the end of the target text.
foo$ matches barfoo,
but does not match foobar.
|
Following four characters (in the table below) are treated
as metacharacters only in specific patterns.
| Escape sequences |
Meanings |
|---|
|
a
|
0x07 (BEL,Alert)
|
|
b
|
0x08 (BS, Back Space)
|
|
d
|
number (equivalent to [0-9])
|
|
D
|
other than number (equivalent to [^0-9])
|
|
f
|
0x0c (FF, Form Feed)
|
|
n
|
0x0a (NL, New Line)
|
|
r
|
0x0d (CR, Carriage Return)
|
|
s
|
white space character
(equivalent to [ trnf])
|
|
S
|
other than white space character
(equivalent to [^ trnf])
|
|
t
|
0x09 (HT, Horizontal Tab)
|
|
w
|
alphabet and number (equivalent to [0-9 a-zA-Z])
|
|
W
|
other than alphabet and number
(equivalent to [^0-9 a-zA-Z])
|
|
xhh,
Xhh
|
hh is hexadecimal of single or double digits (0-9, a-f, A-F)
|